Over the past decade, the term “modern data stack” has come into prominence with the rise of cloud-native software and an increasingly smart, connected world. With workloads shifting to the cloud and an abundance of new, real-time data coming online, enterprises have adopted cloud data warehouses as their systems of record, along with a set of specialized point solutions to aggregate, clean, filter, and analyze this data. This marks an unbundling of the old guard of monolithic, on-prem data infrastructure solutions like Informatica, Teradata, and Alteryx.
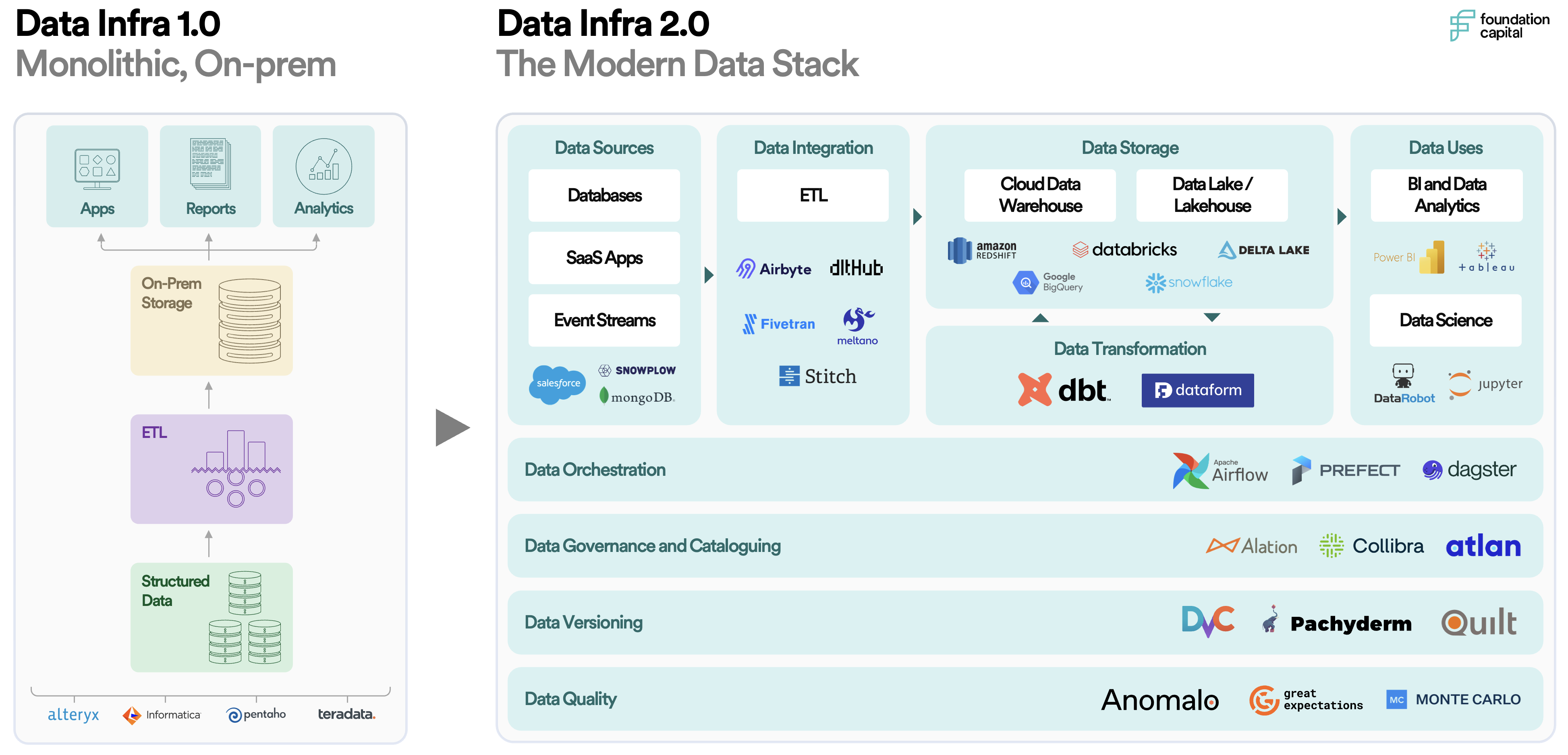
However, with this explosion in data tooling, we’ve lost some of the benefits of the traditional data stack: most notably, the control, visibility, and ease of use that comes with everything living in a single place. Today’s modern data stack has become overly complex, fragmented, and costly to manage. Moreover, for large enterprises, this stack is difficult to both configure and derive value from on an ongoing basis, as it relies on a centralized team of technical, domain experts.
But change is underfoot with advances in generative AI and compute infrastructure. We’re now seeing the advent of a third-generation of data infrastructure: what we call the data hub and spoke. While past articles have focused on how data infrastructure changes for LLM-native apps, our discussion here focuses specifically on data analytics infrastructure. The data hub and spoke promises the best of both worlds, combining the simplicity and ease of use of the traditional data stack with the rich functionality and real-time analytics of modern solutions.
Why now?
The data hub-and-spoke architecture comes in response to three high-level trends whose convergence is reshaping the data infrastructure space.
01 – Macroeconomic pressures on data spending
First, macroeconomic conditions are forcing enterprises to reckon with their spiraling spend on software vendors—and, in particular, data infrastructure vendors. Data practitioners are overwhelmed by the cost and complexity of managing this fragmented set of tools. Moreover, data warehousing compute costs are rising exponentially with the rate and volume of new data being produced, even as the share of data that is truly valuable and business-critical increases linearly. As one example, Instacart’s payments to Snowflake ballooned from $13 million in 2020 to $51 million in 2022. This is not unique: our conversations with CIOs and CDOs indicate that data warehouse spend is almost universally the second biggest line item for enterprises after cloud infrastructure. For many, cutting these costs by at least 25% is their number one priority going forward.
02 – The emergence of generative AI and natural language interfaces
Second, the rise of generative AI and transformer models promises to dramatically change how we interact with data and reshape the data stack from the ground up. One key use case of LLMs is that they enable business analysts to query data with natural language instead of SQL. Rather than this signaling the “death of SQL,” we believe SQL will become more like assembly language, with the complexity of writing SQL queries abstracted away by LLMs.
LLMs also show promise for automating other time-consuming tasks across the data lifecycle, including building and maintaining data pipelines, running ETL jobs, and creating connectors to diverse data sources. While in their early stages today, these capabilities will eventually become the norm for how we interact with data. Both startups and incumbents are making meaningful progress toward this next generation of business intelligence (BI) tools, with a central focus on natural-language interfaces that democratize data access.

03 – The growing value of unstructured, semistructured, and multimodal data
Finally, generative AI is driving increasing interest in storing and making sense of unstructured and semistructured data, along with multimodal data like images, video, and audio. Soon, previously overlooked data sets like Zoom calls, performance review feedback, customer support tickets, and comments from online forums may provide value—with the corollary that enterprises will want to store them. In parallel, important signals will emerge from wider domains of the enterprise, beyond traditional centers like product and engineering. This explosion in the types of data enterprises store, together with the increased heterogeneity of data sources, is another key trend that’s reconfiguring the data infrastructure landscape.
The Data Hub and Spoke
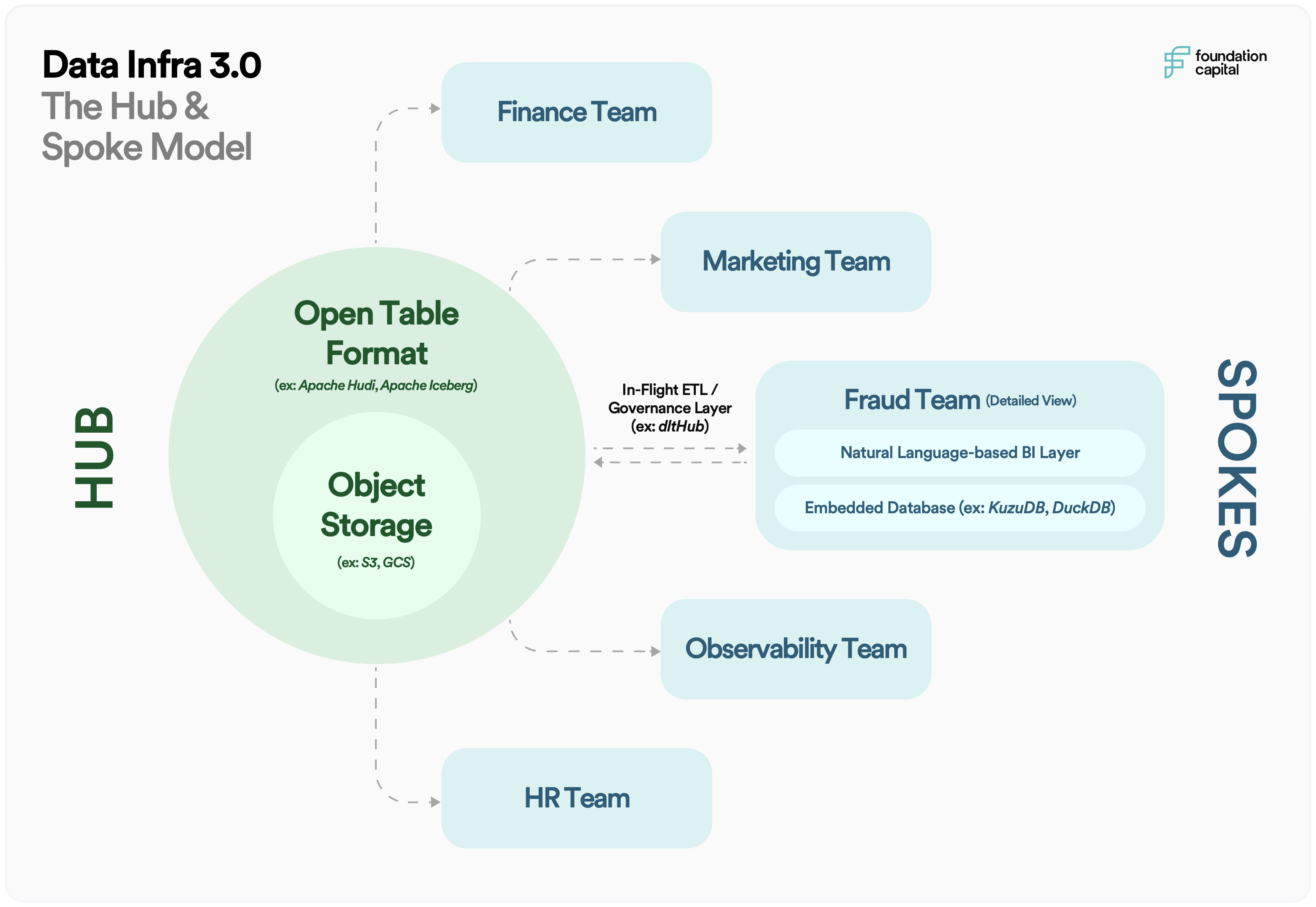
Our view is that these three trends, combined with advances in compute and storage infrastructure, will lead to a third generation of data infrastructure tooling: the hub-and-spoke model. Let’s unpack the subtleties of this model and some of the implications for startups building in the space.
The Hub
In response to cost pressures and growing data volumes, especially in unstructured and heterogeneous data, enterprises are centralizing their data infrastructure into a unified hub. Our view is that enterprises will gravitate toward the most cost-effective data storage options and less preprocessing of data. In the near term, this means a shift from data warehouse architectures to data lakes. Data warehouses like Snowflake are increasingly adding data lake functionality and improving their ability to handle unstructured data and JSON. At the same time, data lakes like Databricks are offering more warehouse functionality, such as ACID transactions. This convergence suggests that a hybrid “lakehouse” model will become the standard for enterprise data storage and management.
Long term, we think more and more data will be housed directly in object stores like S3, GCS, and Azure Storage Account. The emergence of open-source, open-table formats like Apache Hudi and Apache Iceberg (which is being commercialized by our portfolio company Tabular) make it easier to index this data and manage raw, unstructured data at scale. Projects like Trino, commercialized by companies like Starburst Data, are making parallelized, high-performance querying directly on object stores a reality.
The Spoke
At the same time, we also foresee data infrastructure becoming more distributed, with each team within an enterprise operating as a spoke off this central data hub. This new architecture will impact how data teams are organized and how they operate, as well as the tools and technologies they use.
Organizationally, we anticipate a shift toward a data mesh-type architecture where each team owns and manages their own analytics efforts, treating data as a “product” in and of itself. These teams, who are domain experts, exchange data with the central hub and run their own analytics, without relying on a centralized, technical data science or engineering team. Startups like Nextdata are pioneering this trend.
With regard to tools and technologies, we see this as a continuation of the trend of decoupling storage and compute. With the rise of embedded databases like DuckDB (which is being commercialized by our portfolio company Motherduck), SQLite, and KuzuDB, individual teams will be able to choose the database layer that best suits their needs, then run queries and perform analysis on a single node or a local machine. Tools like Neon, which offer serverless database functionality, provide similar flexibility. Longer term, we believe each spoke will operate as a generative-AI-enabled agent, with the ability to pull data in real-time and answer queries autonomously, all while ensuring proper governance.
Opportunities for Startups
Rebundling
The rise of the data hub-and-spoke coincides with a broader rebundling of the data infrastructure stack. In recent years, we’ve seen dozens of venture-backed point solutions emerge for each subcategory of data infrastructure, from cataloging and lineage to quality and governance. Our view is that many of these companies are overfunded and have a limited market opportunity, particularly as CIOs and CDOs continue to cut point solutions that aren’t business critical. Based on their roadmaps, major cloud providers and data platforms like Snowflake and Databricks also seem poised to subsume more data infrastructure categories into their offerings.
In this environment, new vendors that offer all-in-one, bundled services that focus on ease of use will become increasingly valuable and interesting. Point solutions will continue to branch out and expand their offerings. At the same time, we’ll start to see startups leverage the Snowflake and Databricks marketplaces as distribution channels, given their increased prominence as systems of record.
Vertical-specific data stacks
Building on our rebundling thesis, we believe many startups will differentiate from incumbents by offering vertical or domain-specific data stacks. These tools will be all-in-one data stacks that specialize in aggregating and analyzing specific types of data and serving a defined user persona, whether a marketer, security analyst or devops engineer. Another way to think about these types of businesses are “spokes-as-a-service.”
Open-core business models
Open source has been behind many recent data infrastructure innovations, including embedded databases and open-table formats. We see ongoing potential for startups to build atop open-source projects using open-core business models, similar to the last generation of iconic data infrastructure companies like Confluent and Databricks. Many of our conversations with data executives also reveal a preference for open-source tooling, given its customizability and data privacy benefits.
New interfaces for analytics
We see the biggest opportunity for startups in the data hub-and-spoke model at the analytics and business intelligence layer. This is where generative AI is fundamentally transforming the interaction modality, and there is an opportunity to subsume lower parts of the stack. Propelled by advances in serverless computing, we believe the future of BI will be LLM-based. These models will grab data in-flight from object storage, generate transformations, and create visualizations and answers on an ad-hoc basis, with versioning, governance, and quality checks all built in.
In essence, we envision the future as an all-knowing, generative-AI-powered, “data scientist in a box” equipped with full business context. By combining generative AI with intuitive user interfaces, these next-generation BI tools will allow anyone in an organization to explore data with natural language, while the system handles the complexity of finding, preparing, analyzing, and visualizing the appropriate information behind the scenes. Today, the BI market exceeds $25 billion. As new data types come online, and new categories of business users, beyond just dedicated analysts, are empowered to extract insights, we foresee this market doubling over the next decade. The possibilities to enhance business decision-making are immense.
Call for Startups
The future of data infrastructure in the age of generative AI holds tremendous promise. It’s our firm conviction that startups will play a central role in redefining our present-day data stack to better align with the needs and capabilities of LLMs and emerging multimodal models. If you’re building a next-generation data product, we’d love to hear from you! Reach out at viyengar@foundationcap.com.